

 Apache Spark : la version 3.0 du framework open source de traitement des big data est disponible
Apache Spark : la version 3.0 du framework open source de traitement des big data est disponibleavec une amélioration des API Python, une meilleure compatibilité avec le standard ANSI SQL et elle est deux fois plus rapide
Spark est aujourd'hui le framework de facto pour le traitement des big data, la science des données, le machine learning et de l'analyse des données. Apache Spark 3.0 renforce cette position en améliorant considérablement la prise en charge de SQL et Python - les deux langages les plus utilisés avec Spark aujourd'hui - et en apportant de nombreuses optimisations à tous les niveaux.
Parmi les nouveautés les plus importantes, on notera que Spark 3.0 est deux fois plus rapide que Spark 2.4 en s'appuyant sur le TPC-DS, le benchmark de référence dans l'industrie pour mesurer les performances des solutions d'aide à la décision, y compris, mais sans s'y limiter, les systèmes big data. Ce gain de performance a été atteint grâce à des améliorations comme l'exécution adaptative des requêtes, l'élagage de partitions dynamique et d'autres optimisations. La conformité avec le standard ANSI SQL a également été améliorée.
Jusqu'à maintenant, on peut dire que Spark ciblait plus les data engineers, son rôle étant souvent limité à celui d'un ETL (Extract Transform Load). Mais dans cette nouvelle version majeure, le framework open source de calcul distribué s'ouvre davantage aux data scientists et data analysts. Cela se traduit notamment par des améliorations significatives des API pandas, y compris des suggestions de type Python et des UDF (fonctions définies par l'utilisateur) pandas supplémentaires. Spark 3.0 offre encore une meilleure gestion des erreurs Python, et les appels de fonctions R définies par l'utilisateur sont jusqu'à 40 fois plus rapides. Ce sont plus de 3400 tickets Jira qui ont été résolus dans le développement de cette nouvelle version majeure. Nous présentons ici les nouveautés les plus importantes.
Amélioration de Spark SQL
Spark SQL est le module d'Apache Spark pour travailler avec des données structurées et il est très sollicité dans les applications Spark. D'après Databricks, l'entreprise fondée par les créateurs d'Apache Spark, même les développeurs Python et Scala réalisent une grande partie de leur travail avec le moteur Spark SQL. Ainsi, dans Spark 3.0, 46 % de tous les correctifs étaient destinés aux fonctionnalités SQL ; ce qui a permis d'améliorer à la fois les performances et la compatibilité ANSI. En termes de performances, Spark 3.0 a fait environ 2 fois mieux que Spark 2.4 en temps d'exécution total. Cela dit, les trois nouvelles fonctionnalités les plus importantes du moteur Spark SQL sont l'exécution adaptative des requêtes, l'élagage de partition dynamique et l'amélioration de la comptabilité avec le standard ANSI SQL.
Exécution adaptative des requêtes
Lorsque vous écrivez une requête SQL pour Spark avec le langage de votre choix, Spark génère un plan d'exécution qui indique comment le calcul est distribué au sein du cluster. Il est important que le plan d'exécution soit optimal pour une meilleure performance de la requête. Les méthodes d'optimisation de requêtes se concentrent en général sur l'optimisation statique de requêtes. C'est-à-dire que le plan d'exécution de la requête est généré avant l'exécution de cette dernière. Le choix du meilleur plan d'exécution tient compte de statistiques collectées et des coûts estimés. Dans le cas d'une optimisation statique, ce sont les données fournies à l'optimiseur de requêtes avant l'exécution qui sont utilisées, même si elles sont obsolètes au moment de l'exécution. Vous obtiendrez donc un plan non optimal et exécuterez mal votre requête. Vous ne pourrez pas réoptimiser et ajuster le plan de requête en fonction des statistiques collectées lors de l'exécution de la requête.
L'exécution adaptative des requêtes (Adaptive Query Execution, en abrégé AQE), quant à elle, améliore les performances en générant un meilleur plan d'exécution au moment de l'exécution, même si le plan initial est sous-optimal en raison de statistiques de données absentes ou inexactes et de coûts mal estimés. En raison de la séparation du stockage et des traitements dans Spark, l'arrivée des données peut être imprévisible. Pour ces raisons, l'exécution adaptative des requêtes devient plus cruciale pour Spark que pour les systèmes traditionnels.
Élagage de partitions dynamique
Dans les frameworks d'analyse de données tels que Spark, il est important de détecter et d'éviter de lire les données qui ne sont pas pertinentes pour la requête exécutée ; une optimisation connue sous le nom d'élagage de partition. L'élagage de partitions dynamique (Dynamic Partition Pruning, en abrégé DPP) est appliqué lorsque l'optimiseur n'est pas en mesure d'identifier au moment de la compilation les partitions qu'il peut ignorer. C'est un concept utilisé dans les schémas en étoile (une ou plusieurs tables de faits référençant un nombre quelconque de tables de dimension).
Lors d'une opération de jointure, vous pouvez élaguer les partitions que la jointure lit à partir d'une table de faits, en identifiant les partitions qui résultent du filtrage des tables de dimension. Dans environ 60 % des cas (benchmark TPC-DS), l'élagage dynamique de partitions montre une accélération significative (allant d'un facteur 2 à 18) de l'exécution des requêtes.
Conformité ANSI SQL
Spark était quelque peu en retard sur la norme ANSI SQL. Dans la version 3.0.0, le framework de traitement de données massives améliore donc sa compatibilité avec la norme SQL ; ce qui est essentiel pour la migration des charges de travail depuis d'autres moteurs SQL vers Spark SQL.
Amélioration des API Python : PySpark et Koalas
Python est désormais le langage le plus utilisé sur Spark. Pour mettre cela en perspectives, il est important de préciser que 68 % des notebooks sur la plateforme de Databricks l'utilisent.
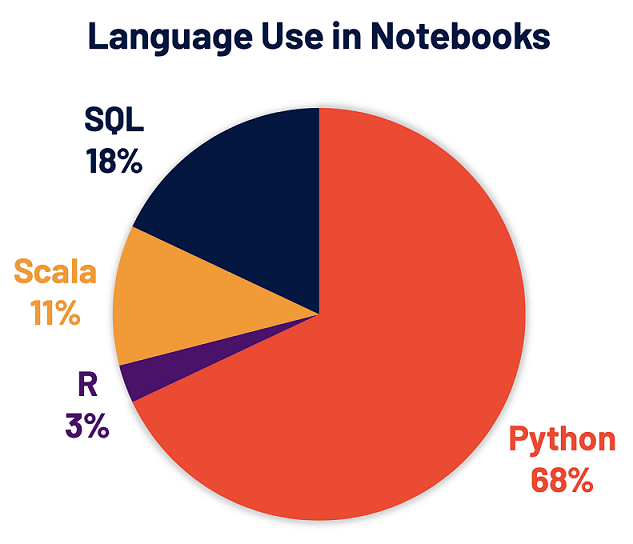
PySpark, l'API Spark pour Python, a plus de 5 millions de téléchargements mensuels sur PyPI, le Python Package Index. De nombreux développeurs Python utilisent l'API pandas pour l'analyse des données, même si elle est limitée au traitement à nud unique.
Python a donc été un domaine clé du développement de Spark 3.0. Il y a eu une accélération du développement de Koalas, une implémentation de l'API pandas au-dessus d'Apache Spark, afin de rendre les data scientists plus productifs lorsqu'ils travaillent avec des big data dans des environnements distribués. Koalas supprime le besoin de créer de nombreuses fonctions (par exemple, le support de graphique) dans PySpark, pour obtenir de meilleures performances sur un cluster. Après plus d'un an de développement, l'API Koalas couvre près de 80 % des fonctionnalités de pandas.
En résumé, les nouveautés de Spark 3.0 pour PySpark incluent des améliorations significatives des API pandas, y compris des suggestions de type Python et des UDF pandas supplémentaires. On note également une meilleure gestion des erreurs Python ; la gestion des erreurs PySpark n'ayant pas toujours été conviviale pour les utilisateurs de Python.
Accélération GPU des traitements dans Spark 3.0
Les processeurs graphiques (GPU) et autres accélérateurs sont très souvent utilisés pour accélérer les charges de travail de deep learning. Pour permettre à Spark de tirer parti des GPU et autres accélérateurs matériels sur les plateformes cibles, cette nouvelle version améliore le planificateur existant en dotant le gestionnaire de cluster d'une fonctionnalité permettant de détecter la présence d'accélérateurs et de les utiliser.
Spark 3.0 reconnaît les GPU comme une ressource de première classe avec le CPU et la mémoire système. Cela permet à Spark 3.0 d'allouer des charges de travail accélérées par GPU directement à des serveurs contenant les ressources GPU nécessaires, car elles sont nécessaires pour accélérer et terminer un travail. Dans Spark 3.0, vous pouvez désormais disposer d'un seul pipeline, de l'ingestion à la préparation des données, jusqu'à la formation des modèles. Les opérations de préparation des données sont désormais accélérées par le GPU et l'infrastructure de data science est consolidée et simplifiée.

Autres changements dans Spark 3.0
Pour cette version de Spark, il faut noter que le support de Python 2 a pris fin. Il en est de même pour les versions de R antérieures à 3.4. Spark 3.0 prend en charge Java 11, Hadoop 3 et supprime la prise en charge de Hadoop 2.6. Soulignons également que Scala 2.12 est désormais pris en charge et que le support de Scala 2.11 a été supprimé.
Spark 3.0 est une version majeure avec plus de 3400 tickets Jira résolus. Ici, nous nous sommes limités aux principales nouveautés pour SQL et Python entre autres, mais il existe de nombreuses autres fonctionnalités que vous pouvez consulter dans les notes de versions ; des fonctionnalités qui couvrent les sources de données, l'écosystème, le monitoring, le débogage, et plus encore.

Sources : Annonce officielle, Notes de version, Databricks, NVIDIA
Et vous ?
 Êtes-vous familier au monde du big data ? Envisagez-vous une carrière dans le domaine ? Quels frameworks utilisez-vous pour le traitement de données massives ? Pourquoi ? Que pensez-vous des nouveautés de Spark 3.0 ?
Êtes-vous familier au monde du big data ? Envisagez-vous une carrière dans le domaine ? Quels frameworks utilisez-vous pour le traitement de données massives ? Pourquoi ? Que pensez-vous des nouveautés de Spark 3.0 ?Voir aussi :
Rubrique Big data : actualités, forums, cours et tutoriels, FAQ Hadoop, etc.
Vous avez lu gratuitement 856 articles depuis plus d'un an.
Soutenez le club developpez.com en souscrivant un abonnement pour que nous puissions continuer à vous proposer des publications.
Soutenez le club developpez.com en souscrivant un abonnement pour que nous puissions continuer à vous proposer des publications.