




I. Qu'est-ce que Hadoop▲
Hadoop est un système distribué, tolérant aux pannes, pour le stockage de données et qui est hautement scalable. Cette capacité de monter en charge est le résultat d'un stockage en cluster à haute bande passante et répliqué, connu sous l'acronyme de HDFS (Hadoop Distributed File System) et d'un traitement distribué spécifique et robuste connu sous le nom de MapReduce.

II. Pourquoi Hadoop dans le cadre de l'IT▲
Hadoop traite et analyse une multitude de nouvelles et anciennes données pour en extraire de la connaissance significative sur les opérations commerciales.
Concrètement les données sont déplacées vers un nœud de calcul. Puis Hadoop va traiter la donnée là où elle se trouve.
Hadoop permet de répondre aux problématiques suivantes :
- l'analyse des événements - quelles séries d'étapes mènent à un achat ou à une signature ;
- l'analyse de clics sur des flux web à grande échelle ;
- l'assurance des revenus et l'optimisation des prix ;
- la gestion des risques financiers ;
- et beaucoup d'autres…
Le cluster Hadoop ou cloud est innovateur dans l'architecture du SI. Certains gestionnaires de ressources (en grid) peuvent être intégrés avec Hadoop. Le principal avantage est que les traitements Hadoop peuvent être soumis et ordonnancés à l'intérieur même du datacenter.
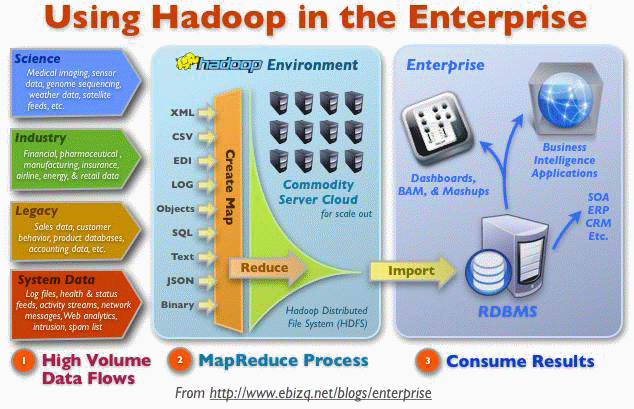
III. Quels sont les types de données que nous traitons aujourd'hui ▲
Les données générées par les personnes conviennent bien aux tables relationnelles ou aux tableaux. Les exemples sont les transactions classiques - achat / vente, stocks / production, changement de statut d'emploi, etc.
Ce sont les données de base gérées par des SGBD relationnels. Dans la dernière décennie, les humains ont généré d'autres types de données comme le texte, les documents (texte ou autres), les photos, les vidéos… Les bases de données relationnelles traditionnelles sont inadaptées à ce type de données, car :
- ces données sont souvent composées d'opinions ou de jugements - des notions qui ne sont pas suffisamment précises ;
- ces données sont à prendre dans leur intégralité, ce qui représente un volume important ;
- ces données ne donneront pas de résultats de requête précis et incontestables : différentes personnes auront des opinions différentes sur ce que l'on appelle de bons résultats ;
- il n'y a pas de réponses binaires claires et précises, les documents peuvent avoir des degrés de pertinence différents.
Un autre type de données est la donnée générée par la machine, machine qui a été créée par l'être humain et qui produit des flux de données qu'il n'est plus possible d'arrêter. Ci-dessous quelques types de données.
- Logs informatiques.
- Télémétrie par satellite (espionnage ou science).
- GPS.
- Capteurs de température et d'environnement.
- Capteurs industriels.
- Vidéos des caméras de surveillance.
- Dispositifs médicaux.
- Capteurs sismiques et géophysiques.
- ...
Selon Gartner, les données de l'entreprise vont croître de 650 % d'ici 2014. 85 % de ces données seront des « données non structurées », et ce segment a un taux de croissance annuel moyen de 62 % par an, taux bien plus important que les données transactionnelles classiques.
IV. Un exemple d'utilisation d'Hadoop▲
Netflix (NASDAQ: NFLX) est une offre de service en ligne de location de DVD et Blu-ray par correspondance et de streaming vidéo aux États-Unis. Elle a plus de 100.000 titres et 10 millions d'abonnés. La société dispose de 55 millions de disques et envoie en moyenne 1,9 million de DVD à ses clients chaque jour. Netflix offre aussi du streaming vidéo sur Internet, permettant la visualisation de films directement sur PC ou sur un téléviseur à la maison.
L'algorithme de recommandation de films de Netflix utilise Hive (qui s'appuie sur Hadoop, HDFS et MapReduce) pour le traitement des requêtes et de la Business Intelligence. Netflix recueille tous les logs du site web qui sont collectés en streaming à l'aide d'Hunu.
Ils analysent 0.6 TB de données sur Amazon S3 via 50 nœuds. Toutes les données sont traitées pour la Business Intelligence à l'aide du logiciel MicroStrategy.
V. Les défis d'Hadoop▲
Concrètement, Hadoop a été fait pour les développeurs. Mais l'adoption à grande échelle et le succès de Hadoop dépendent des utilisateurs professionnels, pas des développeurs.
Des distributions commerciales devront rendre encore plus facile l'utilisation d'Hadoop pour les utilisateurs finaux.

Des langages simples de scripts sont déjà disponibles pour commencer, mais s'éloigner du scripting sera l'objectif à long terme pour atteindre le segment des utilisateurs. On n'y est pas encore. Néanmoins Cloudera essaye de gagner le segment des utilisateurs professionnels, et s'il réussit, ils créera un nouveau marché de Hadoop pour l'entreprise.
Pour mieux illustrer cela, voici une citation de l'équipe de développement Yahoo Hadoop :
«La façon dont Yahoo! utilise Hadoop est en train de changer. Auparavant, la plupart des utilisateurs Hadoop de Yahoo! étaient des chercheurs. Les chercheurs sont généralement gourmands d'évolutions et de fonctionnalités, mais ils ne sont pas regardants sur les pannes. Peu de scientifiques savent même ce que « SLA » (ndt: Service Level Agrement, ou contrat de qualité de service) signifie et ils n'ont pas l'habitude de compter la durée de bon fonctionnement des services. Aujourd'hui, de plus en plus d'applications de production de Yahoo! ont migré sur Hadoop. Ces applications critiques contrôlent tous les aspects du fonctionnement de Yahoo!, de la personnalisation de l'expérience utilisateur à l'optimisation du placement d'annonces. Elles tournent 24/7, et traitent plusieurs téraoctets de données par jour. Elles ne doivent pas planter. Nous sommes donc à la recherche d'ingénieurs logiciels qui veulent nous aider à vérifier que Hadoop fonctionne bien pour Yahoo! et les nombreux utilisateurs Hadoop en dehors de Yahoo! »
VI. Intégration de Hadoop avec un logiciel de gestion de ressources en cloud▲
On peut prendre, par exemple, Oracle Grid Engine 6.2 Update 5. Cycle Computing a également annoncé une intégration avec Hadoop. Il réduit le coût de l'exécution d'applications Apache Hadoop en permettant de partager des ressources avec d'autres applications du datacenter, plutôt que d'avoir à maintenir un cluster dédié pour exécuter des applications Hadoop. Voici une citation d'un client concerné :
« Le logiciel Grid Engine a considérablement réduit pour nous le coût du traitement intensif des données avec Hadoop. Avec sa compréhension native de la localisation des données sur HDFS et le support de soumission de travaux Hadoop, Grid Engine permet d'exécuter des tâches Hadoop exactement dans le même environnement d'ordonnancement que nous utilisons pour des tâches traditionnelles de travaux en parallèle. Avant nous étions obligés de consacrer certains clusters à ce genre de travail ou de faire usage de schémas d'intégration alambiqués, des solutions qui sont à la fois coûteuses à entretenir et inefficaces à long terme. Maintenant, nous avons le meilleur des deux mondes : une grande flexibilité dans un seul système de planification, cohérent et solide. ».
VII. Premiers pas avec Hadoop▲
Hadoop est une implémentation open source des algorithmes de MapReduce et d'un système de fichiers distribué. Hadoop est principalement développé en Java. De toute évidence l'écriture d'une application Hadoop en Java vous donnera beaucoup plus de contrôle et probablement de meilleures performances. Cependant, Hadoop peut aussi être utilisé dans d'autres langages, y compris des langages de script en utilisant ce qu'on appelle le «streaming» : on lit simplement des données depuis l'entrée standard stdin et on écrit sur la sortie stdout.
VIII. Installation Hadoop▲
Pour installer Hadoop, vous aurez besoin de télécharger Hadoop Common (aussi appelé Hadoop Core) surhttp://hadoop.apache.org/common/. Les binaires sont disponibles en Open Source sous licence Apache. Une fois que vous l'avez téléchargé, suivez les instructions d'installation et de configuration.
IX. Hadoop en Virtual Machine▲
Si vous n'avez aucune expérience avec Hadoop, il existe un moyen plus facile pour installer et expérimenter Hadoop. Plutôt que d'installer une copie locale de Hadoop, installez une machine virtuelle de Yahoo!. Cette machine virtuelle est livrée avec Hadoop préinstallé et préconfiguré et est prête à l'emploi. La machine virtuelle est disponible à partir de leur tutoriel Hadoop. Ce tutoriel comprend des instructions bien documentées pour l'exécution de la machine virtuelle et l'exécution d'applications Hadoop. La machine virtuelle, en plus d'Hadoop, comprend Eclipse IDE pour écrire des applications Java basées sur Hadoop.
X. Cluster Hadoop▲
Par défaut, les distributions Hadoop sont configurées pour fonctionner sur une seule machine et la machine virtuelle Yahoo est un bon moyen pour commencer. Cependant, la puissance de Hadoop est sa nature même de traitement et de stockage distribués et le déploiement d'une telle architecture distribuée sur une seule machine n'est pas très probant. Pour tout traitement sérieux avec Hadoop, vous aurez besoin de beaucoup plus de machines. Elastic Compute Cloud d'Amazon (EC2) est parfait pour cela. Une alternative à l'exécution Hadoop sur EC2 est d'utiliser la distribution Cloudera. Et bien sûr, vous pouvez créer votre propre cluster Hadoop en suivant les instructions Apache.
Il existe une grande communauté active de développeurs qui a créé de nombreux langages de script tels que HBase, Hive, Pig, etc. Cloudera propose une distribution avec support.
XI. Remerciements▲
La rédaction Developpez remercie Stéphane Dupont pour sa traduction.
Nous remercions également jacques_jean et ok.Idriss pour leurs relectures attentives et assidues.
Ce tutoriel est une traduction de l'article « Hadoop Tutorial » de Miha Ahronovitz et Kuldip Pabla (Ahrono & Associates) dont l'original est disponible à cette adresse : http://thecloudtutorial.com/hadoop-tutorial.html.